Leveraging Natural Language Processing Techniques for Valuation Analysis
Finding comparable companies for valuation or benchmarking analyses can be a tedious task that is difficult to automate. The use of standard industry taxonomies increases the risk of missing companies that (a) are not classified as expected, (b) are classified differently but are exposed to similar product matrix, or (c) are odd, unique or niche players.
Inspired by the work of Hoberg & Philips (Product Market Synergies and Competition in Mergers and Acquisitions: a text-based analysis, 2010), we developed our own framework that transforms company descriptions into high dimensional vectors. By representing natural text as a vector, we can utilize the benefits of algebra to perform operations like distance calculation (cosine similarity) while capturing the meaning and semantics of the text.
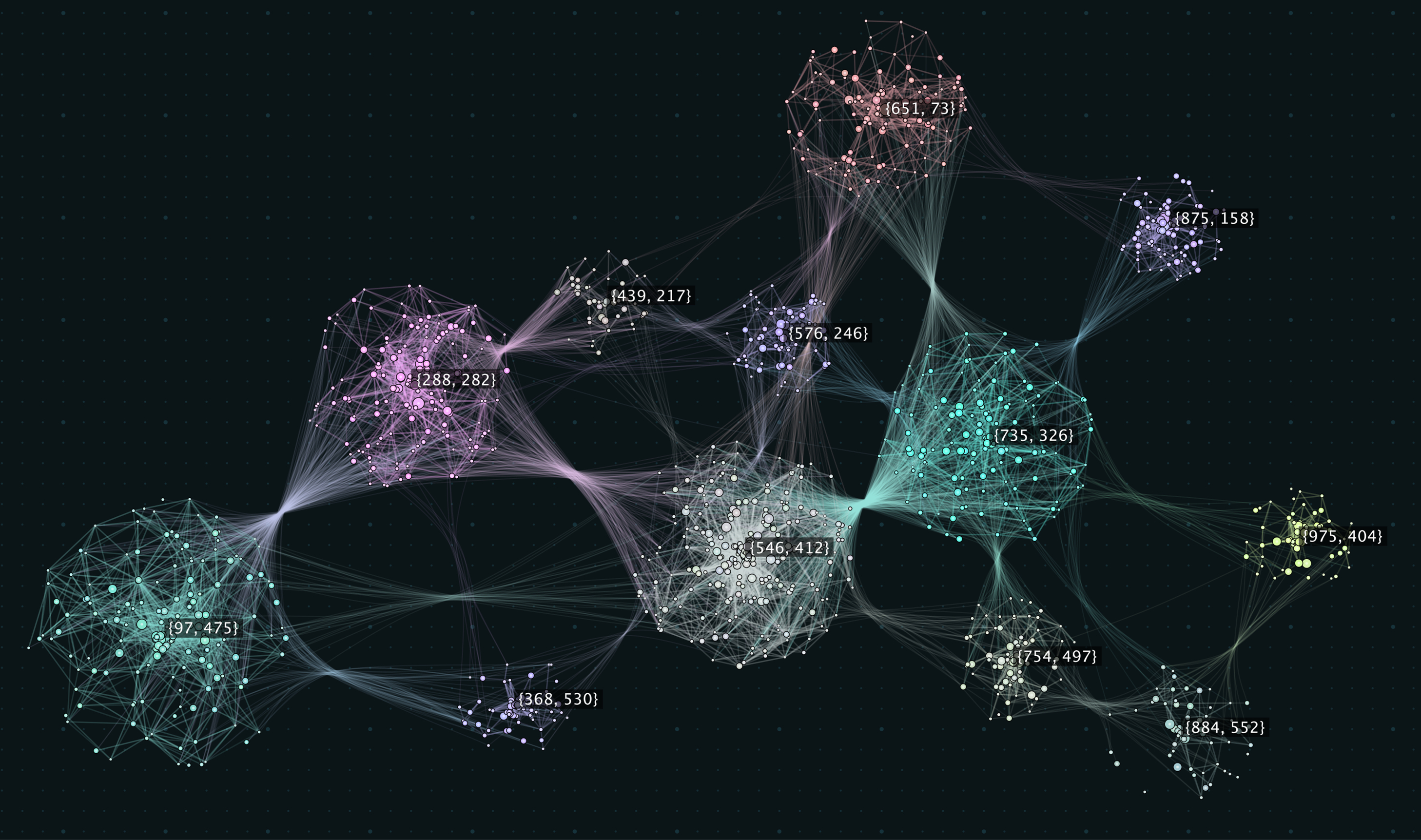
Using this approach on a dataset of 8,000 listed European companies featuring company name and business description, we managed to form a similarity network for each company, as well as perform clustering in order to identify groups of comparable companies (Figure 1).

Say we want a shortlist of listed European companies comparable to our Subject Company. The algorithm automatically provides us with the top X options and are presented as a network graph, where the nodes correspond to companies and the edges correspond to their relationships (Figure 2). The size of the nodes, as well as the distance between them and the edge thickness, are all showing the degree of similarity. The financial analysts can then apply their own reasoning and experience to inspect the graph and make the final peer selection for the valuation.

Although an initial exploration with fairly limited resources spend, our example and result prove the enormous potential for the combination of big data and valuations / corporate finance, saving a significant amount of time while improving quality. The framework can be improved by enriching the original dataset by crawling through more unstructured sources of company information available online. Another application of this framework is to improve credit risk models by more accurately assigning companies to specific peer groups with similar exposures.
If you like to know more about the use of AI in finance, please contact Xavier Schut (+31651461519) or Nontas Alevizos (+31682042676).
